|
DEPARTMENT OF ANTHROPOLOGY- HUMAN BEHAVIOR RESEARCH | simulation
|
|
Modeling Embodied Feedback with Virtual Humans
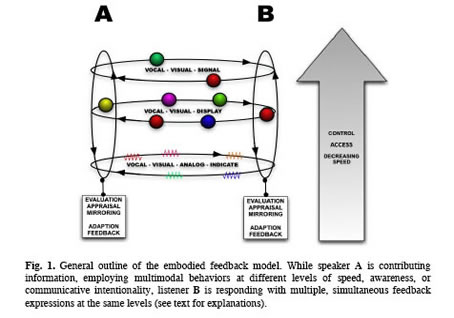
* A.I. Group, Bielefeld University, P.O. Box 100131, D-33501 Bielefeld, Germany In: I. Wachsmuth and G. Knoblich (Eds.), Modeling Communication with Robots and Virtual Humans, LNAI 4930. Berlin: Springer, 2008. In natural communication, both speakers and listeners are active most of the time. While a speaker contributes new information, a listener gives feedback by producing unobtrusive (usually short) vocal or non-vocal bodily expressions to indicate whether he/she is able and willing to communicate, perceive, and understand the information, and what emotions and attitudes are triggered by this information. The simulation of feedback behavior for artificial conversational agents poses big challenges such as the concurrent and integrated perception and production of multi-modal and multi-functional expressions. We present an approach on modeling feedback for and with virtual humans, based on an approach to study “embodied feedback” as a special case of a more general theoretical account of embodied communication. A realization of this approach with the virtual human Max is described and results are presented.
|
In this paper, we presented work towards an account of communicative embodied feedback and, in particular, towards the modeling of more natural feedback behavior of virtual humans. The computational model we have presented extends the architectural layout commonly employed in current embodied conversational agents. At large, it can be considered a row of individual augmentations of the classical modules for interpretation, planning, and realization, affording an incremental processing of the incoming input. One main innovation in this respect was to refine the step size and time scale at which these stages processes input, along with a suitable routing of information via the deliberative or the reactive pathways. One main shortcoming of the interactions currently possible with Max is the need to type in the input, which for instance may result in people focusing their attention on their typing activity and not noticing online feedback given by Max. While spoken language recognition is easily possible in laboratory settings, we want to keep the system as robust as possible in the museum scenario, which affords us with great opportunities for evaluating our models. We are thus planning to stick to the typed input but will discard the need to press enter upon completion of an utterance. Thus, instead of explicitly transmitting the input to the system, Max is to inform the human about having received sufficient information by employing his now developed feedback capabilities. Additional, future work will address the inclusion of additionalinput modalities like prosody or gesture, which will require new models for an incremental segmentation and processing of more analog aspects of communication.
|
|
|
UNIVERSITY OF VIENNA all rights reserved karl.grammer@univie.ac.at |
|